
AWS Data Engineer Course in Hyderabad
cloud upskill certification & 100% placement assistance
In the era of “Data Gravity” a robust architecture isn’t just about storage; it’s about fluidity. We move beyond traditional silos by implementing a Lakehouse Architecture on AWS Training Institute In Hyderabad.
- Duration: 60 Days || Online || all india service || mock intervies || mock tests
- Learners: 3500+ trained || Avg. Salary Hike 65%
FREE Tab + study material home delivery

Our Students are hired by :
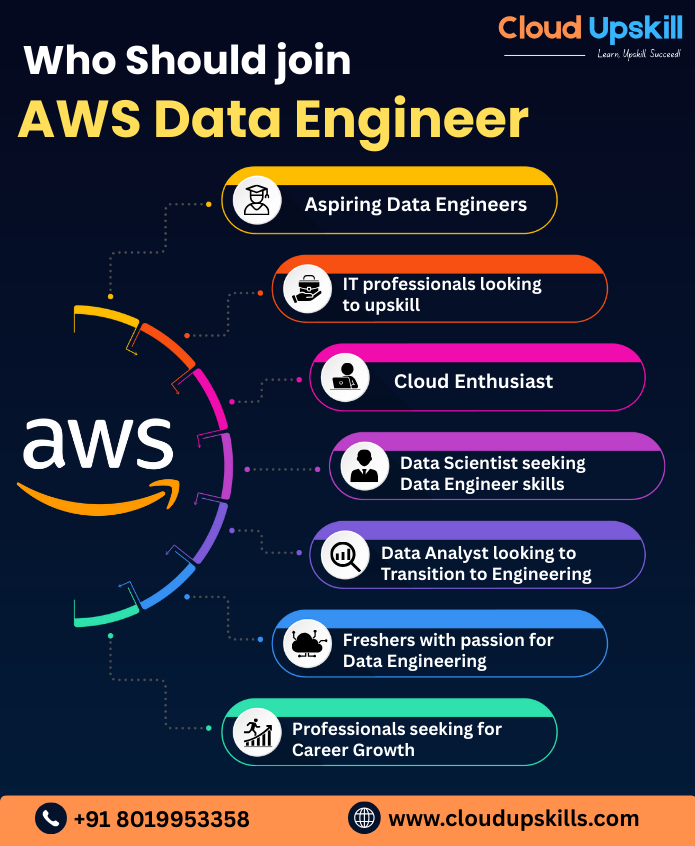
who should Enroll
- Students & Fresh Graduates
- IT Professionals & Developers
- Data Analysts & Scientists
- Business Leaders & Managers
- Content Creators & Marketers
- Entrepreneurs, Startups, Educators & Researchers
Why cloud upskill is the Best AWS Data Engineer Training Institute in Hyderabad
100% Placement Assistance with Top IT Companies and MNCs
Consistently ranked among the best AWS Data engineer training institutes in Hyderabad
60-days Duration
1,000+ Successfully placed in Cloud and Data Engineering roles
Trusted by students and working professionals across India
Online Classroom Mode
Affordable Fees Range
Number of live Projects Completed
What an AWS Data Engineer Is
An AWS Data Engineer is not just someone who knows a few AWS services. It is a specialized role focused on designing, building, securing, and maintaining data platforms and pipelines entirely within (or largely using) the AWS ecosystem, with an emphasis on scalability, reliability, and delivering data as a product to end users. In practice, we bridge traditional data engineering, cloud infrastructure, and data architecture, but with AWS as our primary toolkit. cloud upskill is the AWS Training Institute In Hyderabad
Free Tablet with the Course
Get a tablet bundled with your course (on eligible plans) — making it easier to learn anytime, anywhere.
Comprehensive Study Materials
Well-structured notes, guides, and references provided to support your learning journey.
online & Offline Mock Tests
Practice with exam-style online & offline mock tests to build confidence and track your progress.
24/7 Student Support
Dedicated mentor support round the clock — your questions never go unanswered.
Common Tool’s & Skills You’ll learn from AWS Data Engineer Classes in Hyderabad
Why cloud upskill is the Best AWS Training Institute in Hyderabad


Amazon web services
AWS Data Engineer is the master architect of cloud-based data ecosystems, crafting resilient, high performance pipelines that transform chaotic raw information into actionable intelligence.
With deep expertise in services like Glue, Redshift, Lambda, and S3, they orchestrate seamless data ingestion, transformation, and orchestration, ensuring scalability, security, and cost-efficiency while guiding teams through complex challenges to fuel innovative, data-driven decisions. AWS Training Institute In Hyderabad
After AWS Training
Complete AWS Career path — From Zero to Principal/VP
ENTRY & BREAKING IN (0–2 Years)
- AWS Cloud Support Associate
- Cloud Operations / Junior Cloud Admin
- Junior Cloud Developer / DevOps
- Associate Data/Analytics Engineer
PROFESSIONAL & SPECIALIZATION (2–5 Years)
- Cloud Engineer / DevOps Engineer II
- AWS Solutions Architect (Associate Level)
- Data Engineer II / Analytics Engineer
- ML Engineer (Entry)
- Cloud Security Engineer
SENIOR & LEAD (5–10 Years)
- Senior Cloud Engineer / DevOps Engineer
- Senior AWS Solutions Architect
- Senior Data Engineer / Lead Data Engineer
- Senior ML Engineer / ML Ops Engineer
- Cloud Security Architect
- Cloud FinOps Specialist / Lead
STAFF & PRINCIPAL (8–15 Years)
- Staff Cloud Engineer / Principal Cloud Architect
- Staff/Principal Data Engineer
- Principal Solutions Architect
- Head of Cloud Engineering / Cloud Centre of Excellence Lead
EXECUTIVE & TECHNICAL FELLOW (12–20+ Years)
- Director of Cloud/Platform Engineering
- Director of Data Engineering / Analytics
- VP of Engineering (Cloud/Platform Focus)
- CTO / Chief Architect
- AWS Technical Fellow / Principal Engineer (at Amazon)
- Industry Evangelist / Chief Cloud Officer
AWS Data Engineer Certification Training – Cloud Upskill In Hyderabad
Cloud Upskill offers industry-focused AWS Data Engineer Certification Training in Hyderabad, designed to build strong data engineering skills on Amazon Web Services. The course covers data pipelines, ETL processes, data lakes, analytics, and automation using core AWS services. With hands-on labs, real-time projects, and expert AWS-certified trainers, Cloud Upskill prepares learners for certification success and high-demand data engineering roles.

Our track record & Achievements in AWS Data Engineer Training – Hyderabad, India
99.9% placement Assistance
3000+ successfully course completed students
30+ batches in aws data engineer
10+ years experience in AWS data engineering training
Get more from cloud upskill
Approach our team directly
Reach out, and an academic advisor will promptly follow up with you.
AWS Data Engineer Certification Training journey path – zero to pro
AWS Data Engineer Roadmap
Our industry-aligned curriculum covers end-to-end data pipelines from data ingestion and transformation to storage, analytics, and automation using core AWS services. With expert trainers, hands-on labs, and live project exposure, Cloud Upskill prepares you not just to clear the AWS Data Engineer certification, but to perform confidently in real job roles.Recognized as one of the best IT training institutes in Hyderabad, Cloud Upskill ensures practical learning, career guidance, and placement-focused training.
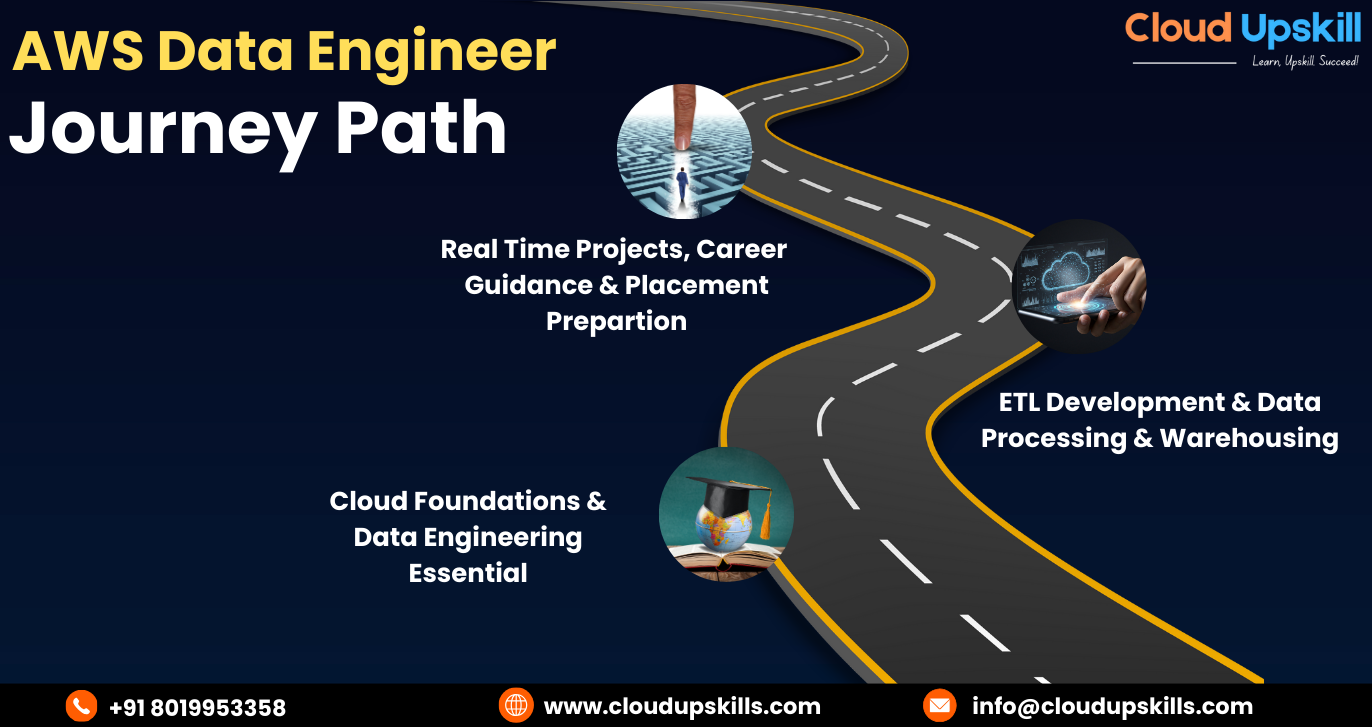
The journey begins with Cloud Foundations & Data Engineering Essentials, where learners build a strong base in cloud concepts, data fundamentals, SQL, and programming logic. This stage focuses on understanding how data flows in cloud environments and prepares learners to think like data engineers rather than just tool users.
Instead of viewing this as a linear checklist, treat it as an expanding scope of influence. Start with Cloud Foundations & Data Engineering Essential as your core mastering not just AWS services but the why behind data patterns (e.g., why choose Kinesis over Kafka Streams in certain architectures). Then, move into ETL Development & Data Processing & Warehousing by building “reference implementations” real, reusable templates for ingestion, transformation, and consumption. The uniqueness here is in treating each skill not as a task, but as a repeatable framework you can later automate, teach, or productize.
The next stage is ETL Development, Data Processing & Warehousing, which forms the core of an AWS Data Engineer’s role. Here, learners design and implement reliable data pipelines, transform raw data into structured formats, and manage scalable data warehouses. This phase emphasizes performance, data quality, and cost-efficient architecture using AWS-native services.
A senior engineer doesn’t just build pipelines they tie each technical layer to a measurable business outcome. For example:
- Cloud Upskill → Not just learning services, but understanding cost-performance trade-offs (e.g., Glue vs. EMR for ad-hoc analytics).
- ETL Development → Designing with data quality and lineage in mind (e.g., integrating AWS DataZone early in the warehousing phase).
- Real-Time Projects → Prioritizing use cases that drive immediate value (e.g., real-time customer personalization over batch reporting).
This approach ensures every tool learned maps to a real-world problem, making you a solutions architect, not just a practitioner.
The final stage covers Real-Time Projects, Career Guidance & Placement Preparation, where theoretical knowledge is converted into practical expertise. Learners work on real-world use cases, handle streaming and batch data scenarios, and gain exposure to industry workflows. This stage also focuses on interview readiness, architectural thinking, and professional confidence required to succeed as an AWS Data Engineer.
- Cloud Foundations: Build a multi-account AWS setup with Terraform, focusing on data security and governance.
- ETL & Warehousing: Develop an end-to-end pipeline that ingests, cleans, and serves data using Glue, Lake Formation, and Redshift and document the decision log (e.g., “Why Parquet over JSON?”).
- Career Guidance: Translate projects into resume-ready STAR stories and GitHub repos that showcase not just what you built, but how it performed (e.g., “Reduced pipeline cost by 40% using step functions and optimal file partitioning”).
This turns learning into tangible proof of senior-level thinking.
how aws Data engineer work's
AWS Training Institute In Hyderabad's
FAQ's
1. What is AWS Data Engineering?
AWS Data Engineering is the practice of designing, building, and managing data pipelines and workflows on Amazon Web Services so that raw data can be collected, stored, transformed, and made ready for analytics and reporting. It typically uses services like Amazon S3, AWS Glue, Amazon Redshift, EMR, and others to move data reliably and at scale from multiple sources into data lakes and data warehouses in a secure, cost‑efficient way.
On Cloud Upskills, AWS Data Engineering focuses on teaching learners how to architect end‑to‑end cloud data solutions: ingesting data in real time or batches, cleaning and transforming it, modelling it for BI tools and machine learning, and enforcing governance so businesses can take faster, data‑driven decisions.
2. Who should learn AWS Data Engineering?
AWS Data Engineering is ideal for software developers, data analysts, database engineers, and cloud engineers who want to move into high‑growth data roles and specialize in AWS‑based analytics solutions. It is also a strong fit for students and career switchers who have basic programming and SQL skills and want to build a future‑proof career in big data, cloud, and AI‑driven analytics. AWS Training Institute In Hyderabad
For Cloud Upskill learners, AWS Data Engineering is especially recommended if:
– You already work with AWS (DevOps, cloud admin, or solution architect) and want to add a data specialization.
– You are a data or BI professional who wants to modernize from on‑premise tools to cloud‑native pipelines and warehousing on AWS.
– You are a student or fresher aiming for your first data engineering or cloud data role and want a structured, project‑oriented learning path.
3. Which core AWS services are essential for a modern Data Engineering pipeline?
To build a scalable, production-grade data ecosystem on AWS, you need to master the “Big Five” of the AWS Data Stack. These services form the backbone of the AWS Lake House Architecture:
Amazon S3 (The Foundation): The ultimate Data Lake storage. It provides infinite scalability and 99.9% durability for raw and curated datasets.
AWS Glue (The ETL Engine): A serverless data integration service. It automates ETL (Extract, Transform, Load), manages the Data Catalog, and handles schema discovery. AWS Training Institute In Hyderabad
Amazon Redshift (The Powerhouse): A high-performance Cloud Data Warehouse. It uses columnar storage and ML-based optimization to run complex SQL queries on petabytes of data.
Amazon Athena (Serverless Analytics): Allows you to query S3 data directly using standard SQL. It is the go-to tool for instant, ad-hoc data analysis without managing servers.
Amazon Kinesis (Real-Time Streaming): Essential for capturing and processing streaming data (like IoT logs or clickstreams) in real-time.
4. What are the top skills required to become a certified AWS Data Engineer?
Becoming an AWS Data Engineer requires a blend of cloud-native expertise and core software engineering principles. In 2026, the industry demands:
Advanced SQL & Optimization: Beyond basic queries, you must master window functions, query tuning, and Redshift performance optimization.
Programming Proficiency (Python & PySpark): Python is the industry standard for writing ETL scripts and managing Big Data processing via Spark.
Data Modelling & Architecture: Expertise in designing Star Schemas, Snowflake Schemas, and partitioning strategies to minimize cost and maximize speed.
Orchestration & DataOps: Familiarity with AWS Step Functions or Apache Airflow (MWAA) for workflow automation, and CI/CD tools like Terraform for Infrastructure as Code (IaC). AWS Training Institute In Hyderabad
Data Security & Governance: Mastering AWS IAM for fine-grained access control and AWS Lake Formation for data masking and security.
5. What is the role of Amazon S3 in AWS Data Engineering?
Amazon S3 (Simple Storage Service) is the core storage backbone of AWS Data Engineering. It serves as a scalable, secure, and cost-effective data lake for storing structured and unstructured data at any scale. S3 enables seamless data ingestion, acts as a central repository for data processing pipelines, and integrates with analytics tools like AWS Glue, Athena, and Redshift for big data analytics and machine learning workflows.
6. What is AWS Glue, and why is it important for data pipelines?
AWS Glue is a fully managed, serverless ETL (Extract, Transform, Load) service that automates data preparation and integration. It provides data cataloging, automated schema discovery, and code-free visual ETL jobs, making it essential for building scalable, automated data pipelines without infrastructure management. Glue accelerates data integration and supports real-time and batch processing, reducing time-to-insight. AWS Training Institute In Hyderabad
7. How does Amazon Redshift support data analytics?
Amazon Redshift is a cloud-based, petabyte-scale data warehouse built for high-performance analytics. It uses columnar storage, parallel query execution, and machine learning optimization to deliver fast queryingon massive datasets. Redshift integrates with BI tools like Tableau and supports data sharing, materialized views, and federated queries, enabling real-time business intelligence and advanced analytics. AWS Training Institute In Hyderabad
8. What is the difference between AWS Glue and Amazon EMR?
AWS Glue is a serverless ETL service focused on data integration, cataloging, and simple transformations with minimal setup. Amazon EMR (Elastic MapReduce) is a managed big data framework for running large-scale distributed processing using Hadoop, Spark, and Hive. Use Glue for automated ETL, choose EMR for complex data processing, machine learning, and custom big data applications. AWS Training Institute In Hyderabad
9. What is real-time data processing in AWS?
Real-time data processing in AWS involves streaming data analytics using services like Amazon Kinesis, Managed Streaming for Apache Kafka (MSK), and AWS Lambda. These tools enable low-latency data ingestion, processing, and visualization for use cases like live dashboards, fraud detection, IoT analytics, and real-time recommendations. AWS Training Institute In Hyderabad
10. What is a Data Lake, and how is it built on AWS?
A Data Lake is a centralized repository storing raw, structured, and unstructured data at scale. On AWS, it is built using Amazon S3 as the primary storage layer, with AWS Glue for Cataloging, Amazon Athena for querying, and Lake Formation for security and governance. This architecture supports big data analytics, AI/ML, and reporting without moving data. AWS Training Institute In Hyderabad
11. How does AWS ensure data security in Data Engineering workflows?
AWS provides end-to-end data security through encryption (at rest and in transit), IAM roles and policies, VPC isolation, AWS KMS for key management, and Lake Formation for fine-grained access control. Services like Macie and CloudTrail add data classification, monitoring, and compliance auditing
12. Which programming languages are commonly used in AWS Data Engineering?
Python, SQL, and Scala are the top programming languages for AWS Data Engineering. Python and Scala are used in Apache Spark (Glue/EMR), while SQL is essential for querying in Redshift, Athena, and relational databases. Knowledge of PySpark, Pandas, and AWS SDKs is highly valuable.
13. What is Amazon Athena, and how is it used in data analysis?
Amazon Athena is a serverless, interactive query service that allows SQL-based analysis directly on data stored in Amazon S3. It requires no infrastructure setup, supports standard SQL, and is ideal for ad-hoc querying, log analysis, and transforming data into actionable insights. AWS Training Institute In Hyderabad
14. What is ETL in AWS Data Engineering?
ETL (Extract, Transform, Load) is the foundational process of moving data from sources to a target system (like a data warehouse). In AWS, ETL is automated using AWS Glue, Step Functions, Lambda, and DMS to cleanse, enrich, and prepare data for analytics, reporting, and machine learning. AWS Training Institute In Hyderabad
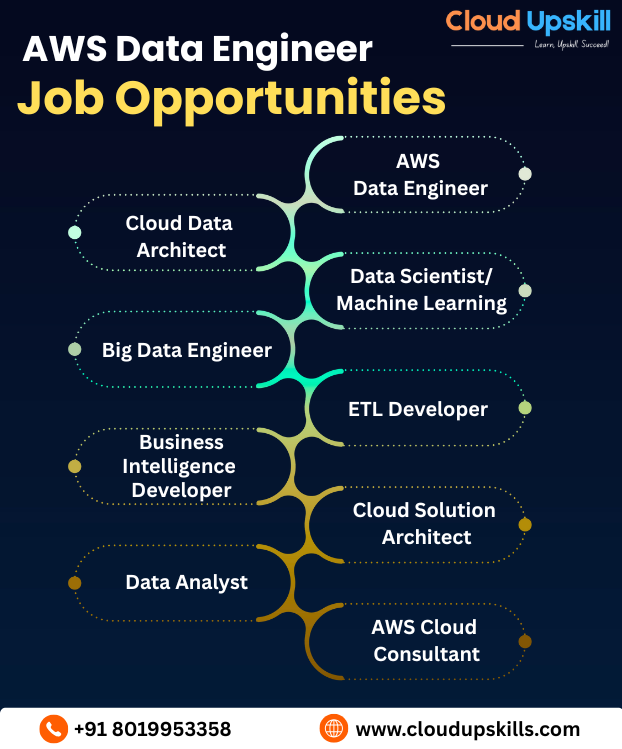
15. What career opportunities are available after learning AWS Data Engineering?
Mastering AWS Data Engineering opens doors to high-demand roles like AWS Data Engineer, Cloud Data Architect, Big Data Engineer, Analytics Engineer, and DataOps Specialist. Industries like finance, healthcare, e-commerce, and tech seek professionals skilled in building scalable data pipelines, cloud analytics, and AI/ML infrastructure. AWS Training Institute In Hyderabad
16. Is AWS Data Engineering suitable for beginners?
Yes! AWS Data Engineering is beginner-friendly with guided learning paths. Starting with basic cloud concepts, SQL, and Python, beginners can gradually master core AWS services (S3, Glue, Redshift). Hands-on projects and certifications help build industry-ready skills for a successful career.
17. How is AWS Data Engineering used in real-world projects?
AWS Data Engineering drives real-time analytics, predictive maintenance, customer 360 platforms, fraud detection, and IoT data processing. Companies use AWS to build data lakes, automate reporting, and enable AI-driven decision-making, transforming raw data into competitive business insights.
18. Which AWS certifications are best for Data Engineers?
The AWS Certified Data Engineer – Associate is the top certification for data engineering roles. Additionally, AWS Certified Solutions Architect – Associate and AWS Certified Big Data – Specialty validate expertise in designing, building, and securing data solutions on AWS.
19. Why is AWS Data Engineering in high demand?
The exponential growth of data, shift to cloud-first strategies, and need for real-time analytics and AI/ML have skyrocketed demand for AWS Data Engineers. Organizations seek professionals who can manage data ecosystems, ensure governance, and drive data-driven innovation at scale. AWS Training Institute In Hyderabad
20. Why choose Cloud Upskills for AWS Data Engineering training?
Cloud Upskills offers industry-aligned, hands-on AWS Data Engineering training designed by certified cloud experts. Our curriculum includes real-world projects, live labs, certification prep, and job assistance, ensuring you gain practical, in-demand skills to excel in cloud data careers. Join thousands of successful learners who have transformed their careers with our premium cloud training programs. AWS Training Institute In Hyderabad
Amazon Web Services Course in Hyderabad
Student Reviews
I completed the AWS Data Engineer course at Cloud Upskill, and it was a great learning experience. The online training, study material, and hands-on practice helped me understand AWS services very well. Best institute for AWS Data Engineer training in Hyderabad.
I have joined in a AWS Data Engineering classes the trainer explained each and every topic clearly without hesitating and I like the services they are providing
Cloud Upskill is a very good institute for learning AWS Data Engineer. The course content is well structured and easy to follow. They give free study material and good support during the course. evaraina AWS data engineering nerchukovali ante cloud upskill suggest chesta .
Sarah Night
Gen AI Dev (Meta)
“I’ve been thoroughly impressed with how engaging and interactive the courses are on this platform. The use of multimedia, quizzes, and live sessions makes learning enjoyable and keeps me motivated.”

